
The National Institute of Korean Language (NIKL) holds an annual international academic conference on the direction of creating Korean-language cultural resources amid the era of artificial intelligence. Shown a scene from last year's conference on Dec. 4, 2024, at the Korea Chamber of Commerce and Industry in Seoul's Jung-gu District. (NIKL)
By Margareth Theresia
The National Institute of Korean Language (NIKL), an affiliate of the Ministry of Culture, Sports and Tourism, is speeding up the development of artificial intelligence (AI) based on Korean under the recognition that data is crucial for national competitiveness.
Support for AI development is being done through the launch of a corpus, or a dataset comprising native digital and older language resources annotated or unannotated, based on the nation's systematic collection of data on Korean. The goal is to develop AI based on Korean and form the basis for AI being part of Hallyu (Korean Wave).
The corpus is data that organizes language information used by people into a form processable by computers. This basic resource helps AI better understand and utilize Korean.
This includes not only written materials like books and newspaper articles but also audio ones including YouTube scripts, blogs and messenger chats. Such corpora are key resources for language research and education as well as AI development.
NIKL is developing three types of corpora: raw, or an electronic version of the original material digitized without separate analysis; annotated, or specific analysis data attached to sentences or clauses; and parallel, which comprises the same content in two or more languages. All three are key factors in development of AI translation know-how.

Based on data from the Korean-foreign language parallel corpus launched in 2021, guidelines for translating the corpus (left) were published in 2023, with an international academic conference held annually. On the right is the poster for last year's conference. (NIKL)
NIKL senior researcher Park Miyoung said, "To create the basis for the AI culture of Hallyu, we started a project to build the Korean-foreign language parallel corpus to support the development of AI interpretation and translation technology centered on Korean as well as secure a growth engine for the language and culture industry."
In 2021, the ministry announced its mid-to long-term strategy for compiling big data on the Korean language and culture industry. The plan is to have NIKL create a parallel corpus focused on foreign languages that lack information on translation into Korean.
Based on analyses of demand for Korean-language education and the need for translation, eight languages were picked: Vietnamese, Indonesian, Thai, Hindi (India), Khmer (Cambodia), Tagalog (the Philippines), Russian and Uzbek.
The Korean-foreign language parallel corpus was produced not through machine translation but that by professionals to ensure high quality. Such experts edit it based on translation guidelines updated every year, thus guaranteeing accuracy.
Data collected from 2021-23 were released on the official site of Modu Corpus by NIKL's Language Information and Resources, with that collected last year to be released by year's end.
The corpus is used extensively to enhance AI translation. Leading AI models such as HyperClovaX of Naver, the nation's largest search portal, and A.dot Service of SK Telecom learn this data.
Thus the corpus is expected to emerge as a valuable practical resource for training translation and interpretation professionals.
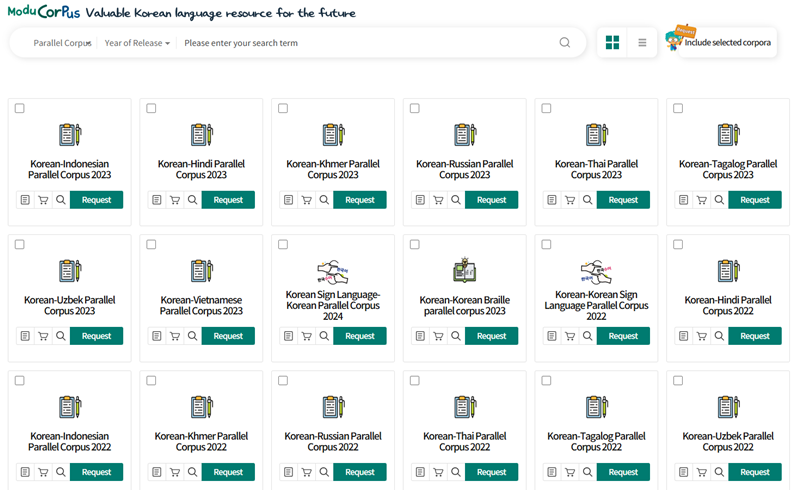
Launched in 2021, the Korean-foreign language parallel corpus is available on the official site of Modu Corpus by NIKL's Language Information and Resources. (Screen capture from website)
"The number of long-term expats in Korea is rising, but translation support in administrative and public services in select languages remains lacking," researcher Park said. "We must continue the second project (2026-30) after the first (2021-25) to further develop machine translation technology."
"To effectively enhance AI performance, we must compile not only text but also other data such as images, voices and videos together," she added. "We will keep developing more diverse corpora to lead the Hallyu of AI culture."
Use of the Korean-foreign language parallel corpus data is free after application on the official website of Language Information and Resources (kli.korean.go.kr/corpus).
margareth@korea.kr